Your next HCP doesn't read your content. Their AI does.
Here's the question every CMO, CDO, and Medical Affairs lead needs to ask themselves today: If a physician asks an AI assistant about your therapeutic area tomorrow, whose clinical evidence will the model actually quote to answer them? Yours, or a competitor's?
Senior physician AI use reached 81% in 2026, up from 38% three years earlier (AMA). IQVIA has called AI "the front door to medical information." Gartner-cited estimates suggest organic search traffic will drop 50%+ in 2026 as HCPs and patients shift from Google to ChatGPT, Perplexity, OpenEvidence, and clinician-specific tools.
For pharma, consumer health, and any regulated industry, this means a structural shift: the first reader of your content is no longer a human making a decision. It is a model that decides whether your evidence is in the answer at all.
This isn't a channel shift. It's a reader shift. And it changes everything that came before it.
For thirty years, we optimised content for a human reader even as our channels shifted from paper brochures to iPads, Veeva iDetailing, and gated HCP portals.
But taking new drugs or maintaining an established brand presence needs more than the directive to 'make MLR-approved content LLM-readable'. It's too vague to act on.
To find the right levers, I built a baseline: right now, today, what does the model actually say about established brands - and on whose evidence?
This week I completed an independent research project using my own AI tools: The 2026 Generics Audit. I executed 96 clinical queries across four major LLM architectures, auditing how they retrieve and cite evidence across six of the world's most prescribed molecules. I purposely chose brands that have been on the market for a very long time solving common issues.
I measured their Share of Algorithmic Trust (SAT)—the percentage ratio of manufacturer-owned, independent peer-reviewed, and skeptical or misattributed sources cited in each model-generated response.
The Macro Findings
Across the entire 96-query dataset, the macro-level results reveal where AI models place their trust:
- 45% Independent Guidelines & Registries: Models default heavily to macro-level clinical guidance (such as NICE, the ESC, or the AHA) and massive observational registries over brand-specific trials.
- 30% Skeptical or Misattributed Data: A massive portion of AI output actively surfaces legacy controversies, patient-facing critiques, or outdated corporate histories.
- Only 25% Manufacturer-Owned Data: And even this number is heavily skewed by over-the-counter (OTC) consumer products. For purely prescription therapies, manufacturer data visibility frequently drops below 15%.
Each data point represents one of the six audited molecules. X-axis: manufacturer-owned citation share. Y-axis: independent/guideline citation share. Quadrant labels indicate strategic risk posture.
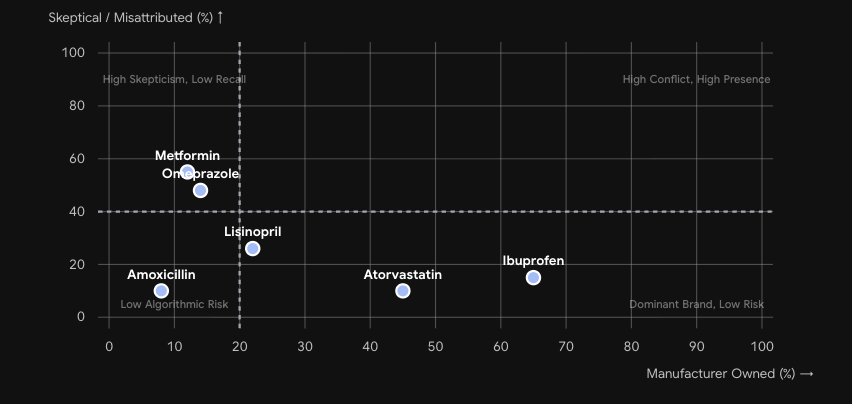
The skepticism dimension. Metformin and Omeprazole show the highest misattribution rates — over 50% of citations in the retrieval layer are adversarial or legacy controversy content.
Four Modes of Algorithmic Failure
When you zoom in on specific molecules, the AI retrieval patterns expose four distinct algorithmic failure modes that are quietly burying brand authority:
1. Buried Evidence (Metformin)
12% Manufacturer Share / 55% Skeptical Share
For complex, long-term chronic therapies, independent skepticism and lifestyle narratives dominate the retrieval layer. On Metformin, 55% of the models' citation footprint points to independent longevity debates (like the MASTERS exercise-blunting trial) and off-label controversies. The manufacturer's core clinical utility data is effectively buried.
2. The Absent Originator (Amoxicillin)
8% Manufacturer Share / 82% Independent Share
For commoditized essentials, the originator brands have been entirely erased from the algorithmic memory. The models cede 82% of the citation share to national surveillance guidelines and registries (such as IDSA/ATS). The brand owners have entirely ceded the conversation.
3. Over-Saturation (Ibuprofen)
65% Manufacturer Share / 20% Independent Share
Over-tuning legacy consumer SEO can backfire in the agentic era. On Ibuprofen, consumer brands dominate 65% of the citations. Because the models' output fails to cite independent, balancing clinical guidelines, the summary reads like a sponsored ad—instantly destroying clinical credibility with a searching physician.
4. Misattributed Evidence (Lisinopril)
22% Manufacturer Share / 26% Misattributed Share
The models are deeply confused by historical corporate M&A. Citing long-dissolved corporate entities from the 1980s, the models' "corporate memory" is frozen in time, actively breaking the modern manufacturer's chain chain of clinical authority on the safety questions that matter most.
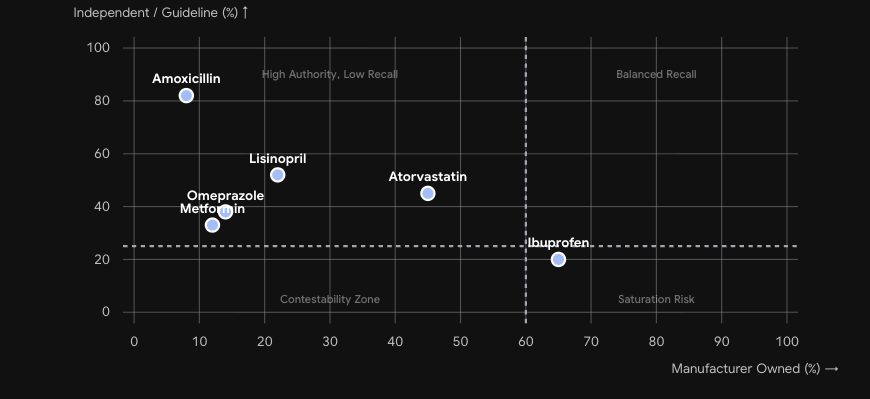
Aggregated across all four LLM architectures. Amoxicillin sits in the High Authority / Low Recall quadrant. Ibuprofen approaches Saturation Risk. Metformin is deep in the adversarial zone.
The Architecture Bias
Which failure mode your brand experiences depends largely on which model your HCP is using. The audit revealed three distinct retrieval architectures. Each creates a different risk profile:
- Guideline-Weighted Retrievers (e.g. Google Gemini): Prioritise systemic, physiological explanations and macro-clinical guidance. For a brand's evidence to surface here, it must be tightly integrated with and cited alongside respected medical society guidelines.
- Controversy-Weighted / Real-Time Retrievers (e.g. Grok): Heavily index on recent news, observational risk registries, and off-label controversies, naturally amplifying the "Buried Evidence" failure mode.
- Historical / General-Purpose Retrievers (e.g. Claude or ChatGPT): Offer structured, clinically practical summaries but rely on historical brand footprints and are most vulnerable to legacy M&A confusion.
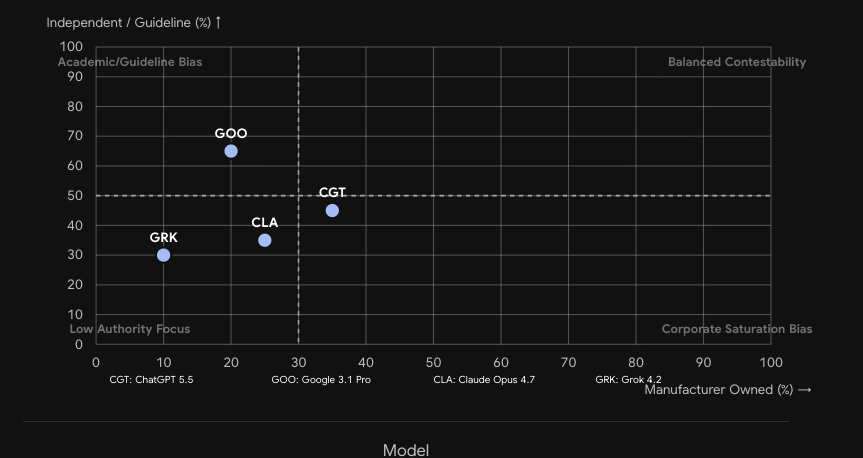
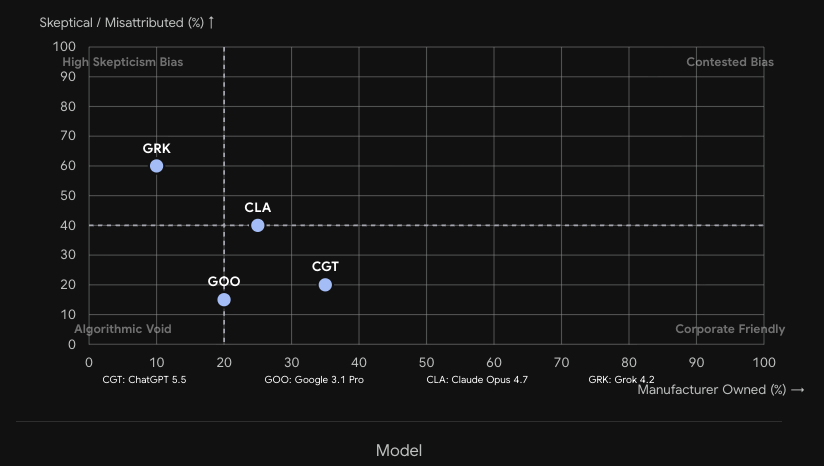
Each point is one LLM architecture. Grok (GRK) sits highest on skepticism bias. Google (GOO) dominates the academic/guideline quadrant. Claude and ChatGPT occupy the centre — historically reliable but vulnerable to legacy M&A confusion.
“Traditional ‘Share of Voice’ measurement is no longer sufficient. Brand owners need to define a Share of Algorithmic Trust KPI.”
The Remediation Plan
What LLMs reward is exactly what your MLR process already produces: explicit claims, named sources, factual consistency, and clean citation trails. The evidence base exists. It's the content architecture that's broken. The MLR-approved PDF is no longer a sufficient digital asset class on its own; it must be complemented by structured, machine-readable claim architectures.
Four places for pharma leaders to start before Q3:
- Run an Algorithmic Audit: Query your top 10 HCP questions. Document what's cited, what's missing, and what's flat-out wrong. (Warning: it produces an uncomfortable afternoon).
- Audit your Content Supply Chain for machine-readability: Trace how a clinical claim moves from medical affairs to MLR approval to final asset. Are you locking pre-approved clinical claims inside flat, uncrawlable PDFs, or are you structuring them as semantically tagged, modular blocks? Re-architect the supply chain so "machine-readable" is a native, automated output of your existing CMS.
- Deploy LLM Optimization (LLMO) Tooling: Traditional SEO tools are blind to model retrieval. To solve this at scale, enterprise teams must integrate specialized LLMO platforms and structured schema managers directly into their active MarTech stack to dynamically monitor and tune how different AI models index their evidence.
- Assign Ownership: Put "Share of Algorithmic Trust" on someone's scorecard. If no one owns the model's output, no one will fix it.
The reality is clear: if you cannot verify whose clinical evidence the models are quoting about your brand today, you are already losing share of trust.
The pharma orgs that win the next three years won't be the ones with the most AI tools. They will be the ones doing the hard, foundational work of making the world's most rigorous evidence base readable by the world's newest reader.
Methodology & Limitations: Findings are based on 96 structured probes across 4 LLMs conducted May 2026 by Richard Armitage for the The Outcome Evolution blog. This study measures AI search-retrieval and citation patterns only — it is not an evaluation of the clinical safety or efficacy of any molecule, nor a peer-reviewed clinical trial. LLM outputs are non-deterministic and change frequently; results reflect a point-in-time snapshot, not stable model properties.